
一文说清楚数据集成中的流处理与批处理的区别
作者: RestCloud at:2024-09-14 14:30:56
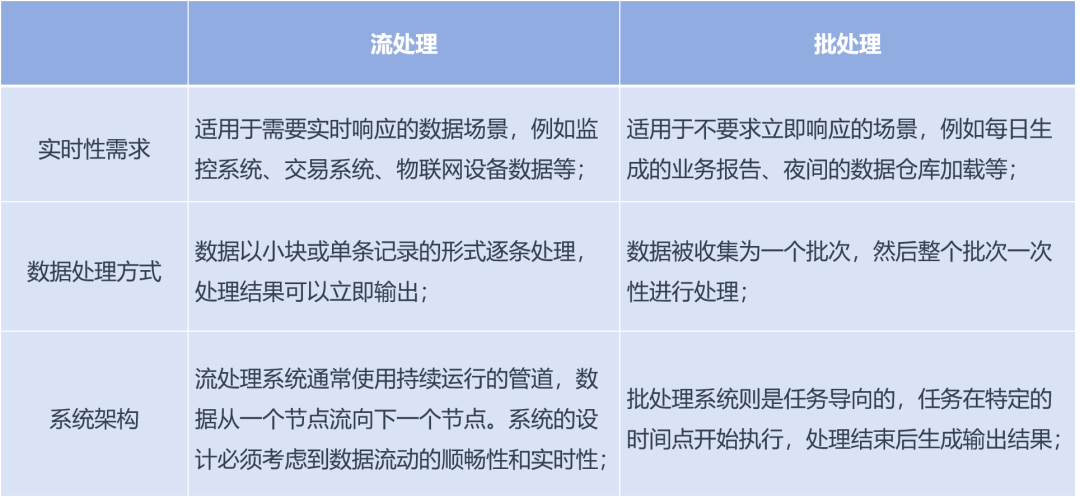
流数据处理和批数据处理之间的区别主要在于数据的处理方式、时间性、架构设计和适用场景。虽然批处理系统和流处理系统都可以处理数据,但它们处理数据的方式和目的不同,以我们来对“流数据处理”和“批数据处理”进行差异分析。
流数据处理 VS 批数据处理
流数据处理(Stream Processing)
定义: 流数据处理是指实时、连续地处理数据流。数据在被产生或接收后立即处理,并不需要等待所有数据到齐。数据的处理和传输是“逐条”进行的。
特点
实时性: 数据一旦进入系统,就会被立即处理,这使得系统能够处理实时的数据流,如来自传感器、点击流日志、金融交易等。
数据流的无限性: 流数据通常是无限的,数据持续不断地被生成和处理,系统需要持续运行。
低延迟: 由于数据被实时处理,系统响应时间非常短,通常在毫秒或秒级。
架构: 流处理系统通常需要处理器、队列、缓存等组件,以支持高吞吐量和低延迟。
批数据处理(Batch Processing)
定义: 批数据处理是指在一个预定时间内收集一批数据,然后一次性对这批数据进行处理。数据是成批处理的,而不是逐条处理。
特点
处理完整的数据集: 批处理通常在所有数据收集完毕后进行,这意味着处理的数据集是固定大小的(如每日、每小时的数据)。
高吞吐量: 由于数据可以一次性处理,批处理通常能处理大量数据,但响应时间较长。
架构: 批处理系统通常采用调度器、任务队列和数据仓库等组件,可以在处理过程中利用磁盘存储,而不依赖于内存。
延迟: 批处理通常不是实时的,处理的延迟可能是分钟、小时甚至更长。
为什么有流和批之分
流内存数据对象 VS 流与批的区别
内存中的数据对象:无论是流处理还是批处理,数据在处理过程中可能都会暂时存储在内存中。但是,两者在如何管理和使用这些内存数据对象上有所不同。
流处理的内存使用通常是短暂的,因为数据会迅速流过数据处理节点。
批处理的内存使用可能会更集中,因为需要在内存中处理完整的批次数据,这可能导致需要更大的内存资源或频繁的磁盘 I/O。
典型流处理与批处理平台
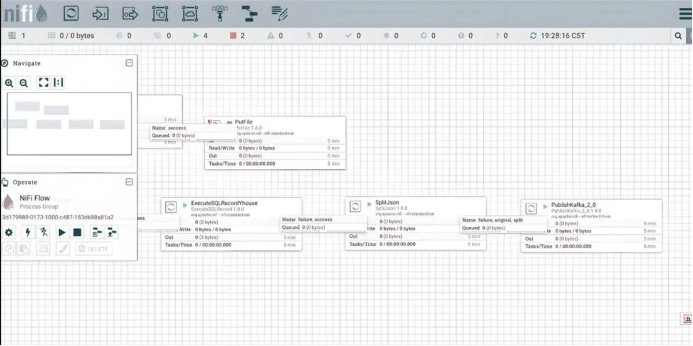
Apache NiFi
数据流从一个处理器流向下一个处理器,可以随时对数据进行处理、过滤、转换、路由等操作。数据可以是不断流入的流数据,如 IoT 传感器数据。每一条数据进入系统后都会被立即处理,处理完之后数据就会被传递到下一个处理节点,整个流程是实时进行的。
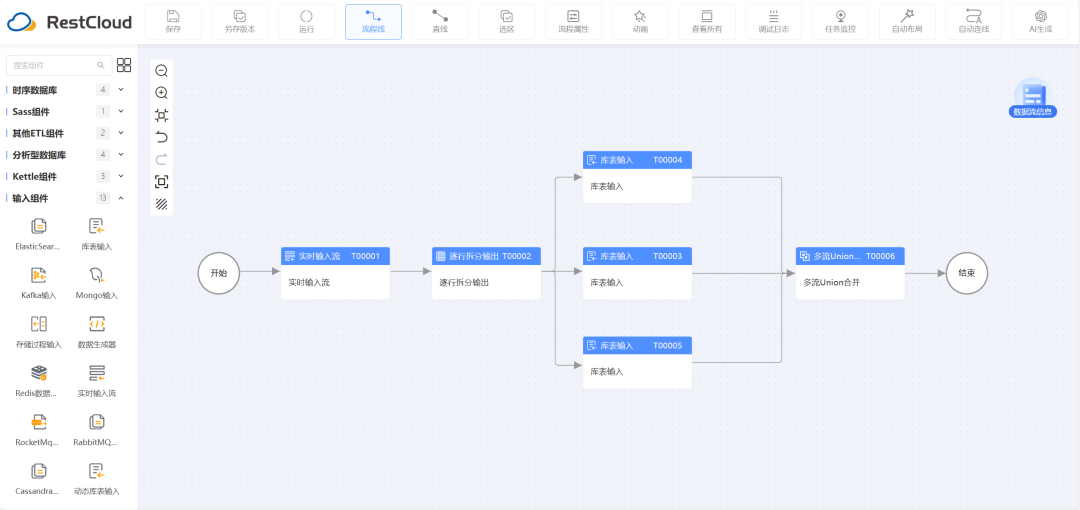
ETLCloud
数据通常是在任务开始时从源头读取并加载到内存中,然后按照定义的转换步骤进行批量处理。比如每小时从数据库中读取一个表的所有记录,然后对这些记录进行清洗、转换,最后加载到目标数据库。
数据处理是在任务执行时才进行,所有的转换操作是在所有数据都准备好之后一次性完成的。虽然也可以对实时数据流处理,但是在框架上不是专门为流处理设计的,更适合于进行实时流的微批处理。
总结
流处理: 强调实时性和持续性,适合处理无边界的、连续产生的数据流。Apache NiFi 通过“逐条处理”的方式,实现了流数据的实时处理。批处理: 强调对固定批次数据的集中处理,适合处理边界明确的数据集。
ETLCloud通过“批量处理”的方式,一次性对一批数据进行处理。流处理和批处理虽然都可以在内存中处理数据对象,但它们的处理逻辑和设计理念不同,适用于不同的应用场景。
